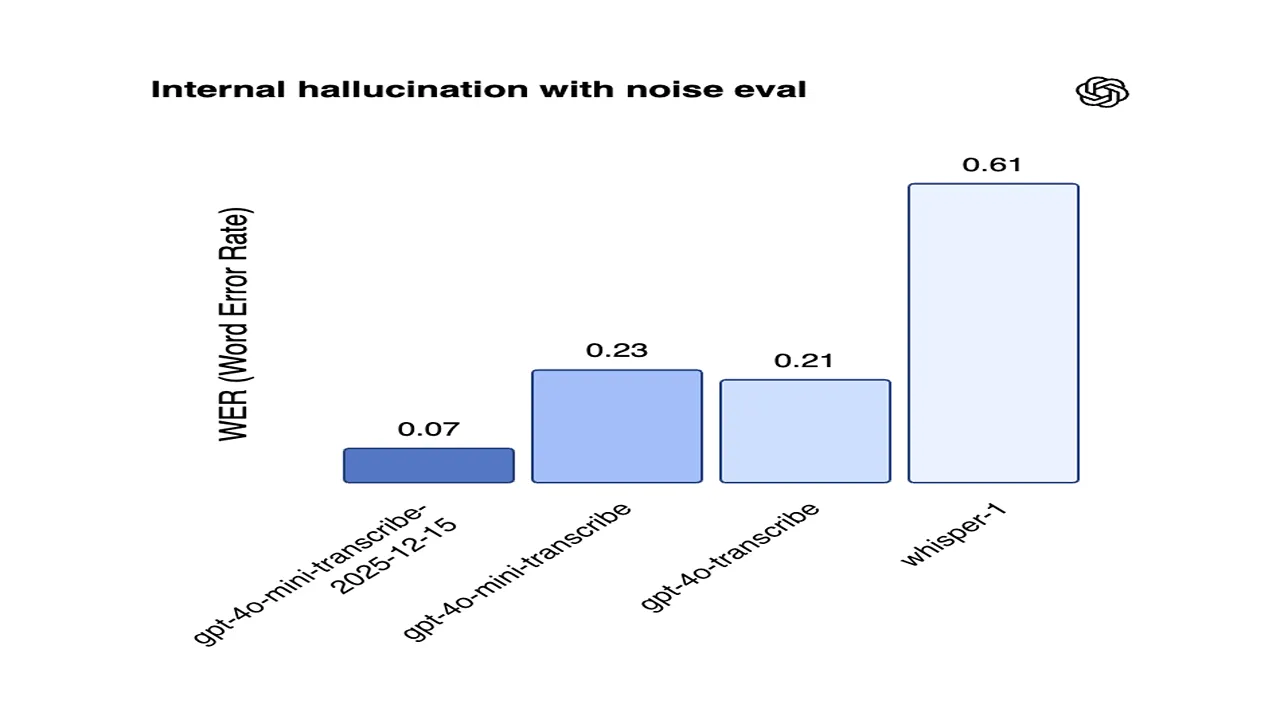
Company engineers also note a reduction in "hallucinations" when transcribing long audio segments. For developers, this enables the creation of more reliable and responsive voice agents capable of conversing with minimal latency. The update is already available in the platform console and does not require architectural changes to existing applications—developers simply need to point to the new model IDs. Experts believe this move strengthens OpenAI's position in the conversational AI sector.
Source: OpenAI Developer Community
OpenAIRealtime APIDevToolsAudio Models