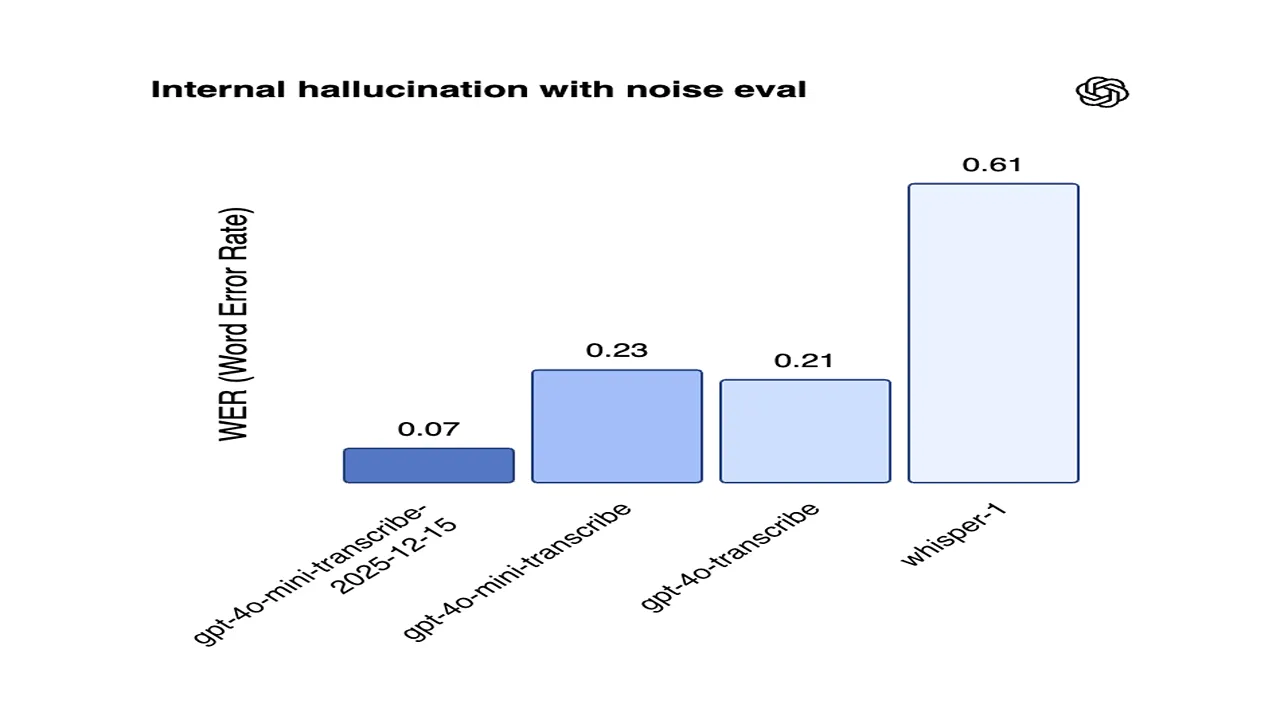
Los ingenieros de la compañía también señalan una reducción en las "alucinaciones" al transcribir segmentos de audio largos. Para los desarrolladores, esto significa la capacidad de crear agentes de voz más confiables y receptivos, capaces de mantener diálogos con una latencia mínima. La actualización ya está disponible en la consola de la plataforma y no requiere cambios arquitectónicos en las aplicaciones existentes; solo basta con apuntar a los nuevos ID de los modelos. Los expertos creen que este movimiento fortalece la posición de OpenAI en el sector de IA conversacional.
Fuente: OpenAI Developer Community
OpenAIRealtime APIDevToolsAudio Models